
On the Expected Subword Complexity of Random Words
In this article, we study the expected subword complexity of random words and some of its properties.
We define the subword complexity of a word as the number of nonempty distinct subwords in it. For example, the word abb has 5 distinct nonempty subwords: a, b, ab, bb and abb, thus its subword complexity is 5. Here arises the question: let $A$ be the alphabet with the cardinality of $m$, and let $w$ be a random word distributed uniformly in $A^n$, then what’s the expected subword complexity of $w$?
It’s easy to show that we can turn this problem into computing the sum of subword complexities of all words in $A^n$. Let’s consider this question in a reversed way. We enumerate all the words in $B_n=(A^1\cup A^2\cup\dots\cup A^n)$, and for each word we compute how many words in $A^n$ contains it. Though this step does not reduce the time complexity and even increases it, but it can observed that some for a group of words in $B_n$, the amounts of words in $A_n$ containing them are exactly the same.
More precisely, let $w$ be a finite word, and we define the autocorrelation polynomial $c_w(x)$ as a polynomial related to $x$, in which $[x^i]c_w(x)=1$ if and only if the word $w$ has a period of length $i$, and otherwise $[x^i]c_w(x)=0$. Specially, we define that $[x^0]c_w(x)=1$ for any $w$. Let $e_{w,i}$ denotes the number of words containing $w$ with length $i$ and an alphabet with cardinality of $m$ and $E_w(x)$ be the generating function of $e_{w,i}$. Then we have:
$$
E_w(x)=\frac{x^{|w|}}{(1-mx)(x^{|w|}+(1-mx)c_w(x))}
$$
I gave the detailed proof of it here (Chinese).
Let’s assume that we already obtained all possible $c_w(x)$ for each length $k$ ($1\le k\le n$) and their populations (how many words $u$ in $A_k$ has that autocorrelation polynomial) respectively, we can just simply sum $E_w(x)\times\text{pop}(c_w(x))$ and obtain the final answer.
Let autocorrelation vector $\phi(u)$ be a binary vector of length $|w|$ and $\phi(u)_i=[x^i]c_w(x)$, and $W_v$ be the set form of $v$ where $W_v={i|v_i=1}$. Then we denote the population of $c_w(x)$ by $f_v$. Now we should compute $f_v$ for each possible $v$.
Let’s consider the inclusion-exclusion principle. Firstly, we compute the number of words having “at least” the periods in $v$. That means, the word $u$ should satisfy that $W_{\phi(u)}\supseteq W_v$. We denote this amount by $S_v$. This value can be easily computed in $O(n^2)$ using union-find algorithm. More specifically, since we know that the indices of a word $w$ ($i=1\dots|w|$) having given periods can be divided into several groups in which two indices $p,q$ are in the same group if and only if $w_p$ must equal to $w_q$. We call the number of such groups ($K_v$) as the number of free elements of $v$. Then it’s easily shown that $S_v=m^{K_v}$. And then we can know that:
$$ f_v=S_v-\sum_{j|i\subset j}f_j $$Now we can compute the answer for a given pair $(n,m)$.
Let’s observe the generating function $E_w(x)$. Firstly, since $E_w(x)$ is a formal power series the fraction can be seen as a product of two formal power series. And it’s obvious that terms $x^py^q$ with $p<q$ does not exist since all the $y$ in $E_w(x)$ are appeared along with $x$. So we can assert that when $n$ is given, the answer of our question is $F_n(m)$ where $F_n$ is a polynomial and $\deg F_n(m)\le n$. Here gives $F_n$ for $n=1,2,3$:
$$ \begin{aligned} F_1(x)&=x\\ F_2(x)&=-x+3x^3\\ F_3(x)&=-3x^2+6x^3 \end{aligned} $$And here lists all the coefficients from lower degrees to higher ones of $F_n$ for $n=0\dots60$. Some discoveries are listed below:
- $[x^0]F_n(x)=0$: Since we can not form any string when the alphabet is an empty set, this is an obvious result.
- $[x^n]F_n(x)=\frac{n(n+1)}2$: This is a conjecture.
Now we describe a method for enumerating $c_w(x)$ and computing $K_{\phi(w)}$ for each of them. We consulted the prediction used to judge whether a binary vector is an autocorrelation vector mentioned by Guibas and Odlyzko in Periods in Strings. Let $\pi(v)=\min\left\{t|v_t=1\land t\ne0\right\}$, in other words, $\pi(v)$ denotes the minimum non-zero period in $v$. Specially, we define that $\pi(v)=+\infty$ when such period does not exist. We give the definition of the recursive prediction $\Xi$ below:
$v$ satisfies $\Xi$, if and only if $v$ is empty, or $v_0=1$ and $v$ satisfies one of the two disjoint constraints below:
- $\pi(v)\le\left\lfloor\frac{|v|}2\right\rfloor$, and for each multiples of $\pi(v)$, $k$ ($k<|v|$), we have $v_k=1$; and, when we define that $r=\pi(v)(\left\lfloor\frac n{\pi(v)}\right\rfloor-1)$, we have $\pi(w)\ge p$ or $\pi(w)>(n-r-\pi(v))+(\pi(v),\pi(w))$.
- $\pi(v)>\left\lfloor\frac{|v|}2\right\rfloor$, and $v_{r\dots(|v|-1)}$ satisfies $\Xi$.
We can enumerate all autocorrelation vectors based on the idea of this prediction. When we enumerate all the autocorrelations vectors of length $n$, we record a binary vector $q$ along the way, $q_i=1$ means that the final autocorrelation vector $v$ must satisfy $v_i=1$. We enumerate $\pi(v)$ firstly, and obviously we should have $q_i\ne1$ for $1\le i<\pi(v)$. And then we have three cases:
- $\pi(v)\le\left\lfloor\frac{|v|}2\right\rfloor$. We check whether the elements in $q$ conflict with $\pi(v)$ (in other words, whether a $i$ exists such that $p\nmid i$ and $q_i=1$), and then we mark $q_i=1$ for each multiples of $p$, $i$ where $i<|v|$, and then we let $n’=n-r$ and continue our enumeration recursively.
- $\pi(v)>\left\lfloor\frac{|v|}2\right\rfloor$ and $\pi(v)\ne+\infty$. We can just let $n’=n-\pi(v)$ and continue the enumeration.
- $\pi(v)=+\infty$. That means we already find a possible autocorrelation vector, and we don’t need to recurse anymore.
According to measured time, the time this algorithm takes to find all $c_w(x)$ is proportional to the total number of distinct $c_w(x)$. Now we need to compute $K_{\phi(w)}$ at the same time. We describe this process in three cases same to above (the link in the graph below means that two parts of the string are exactly the same):
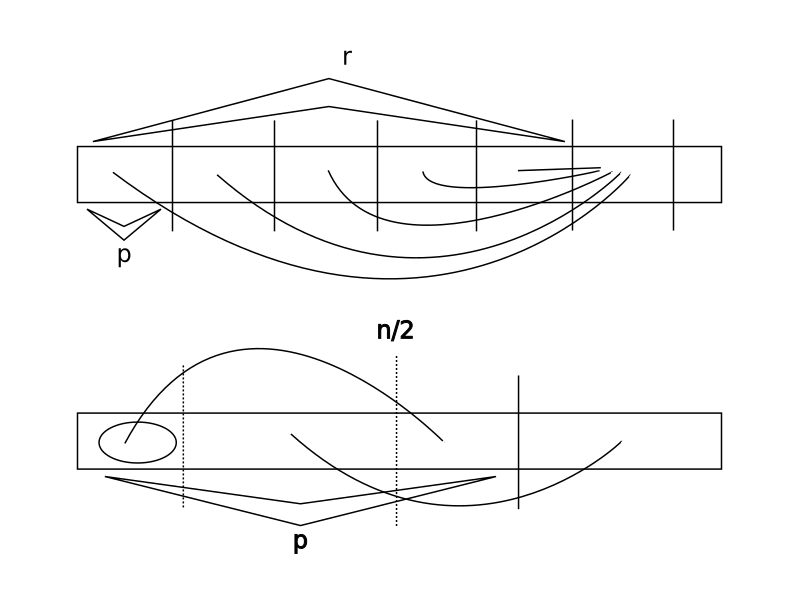
- $\pi(v)\le\left\lfloor\frac{|v|}2\right\rfloor$ (the first graph). Now $K_v$ is just equal to the $K$ of the rest part.
- $\pi(v)>\left\lfloor\frac{|v|}2\right\rfloor$ (the second graph). Now $K_v$ is equal to the length of the circled part plus the $K$ of the rest part.
- $\pi(v)=+\infty$. Now we have $K_v=0$.
An example program is given here which can give out all the autocorrelation vectors along with their populations in less than five minutes on my computer.
Now the bottleneck of the time complexity is to calculate $f_v$, which has the time complexity of $O((\text{number of distinct v})^2)$. If we want to reduce that time complexity, we shall maintain a data structure supporting following operations:
- $insert(x, v)$: insert a pair $(x,v)$ where $x$ is a set of elements ranged between $[1,n]$ and $v$ is an integer.
- $query(y)$: query the sum of $v$ in $(x,v)$ where $x\supseteq y$.
It’s easily noticed that we can divide the set into two parts as a binary number and maintain it. However, it does not reduce the time complexity significantly. If you have any good ideas, feel free to contact the author.
On the Expected Subword Complexity of Random Words
https://mivik.moe/2021/research/expected-subword-complexity-en/
